
From Raw Data to Insights: The Art of Feature Engineering
"Unlocking the Power of Data: The Journey from Raw Data to Actionable Insights through Feature Engineering"

What is Feature Engineering?
Feature engineering or feature extraction or feature discovery is the process of using domain knowledge to extract features from raw data.

Importance of Feature Engineering:
Let’s say that if you are having a great dataset with huge number of rows and columns but you didn’t performed feature engineering and trained your model without it, it is pretty sure that a model trained on a poor dataset with less number of rows and columns will perform far better.
Let’s see a example of how performance and accuracy are affected by feature engineering:
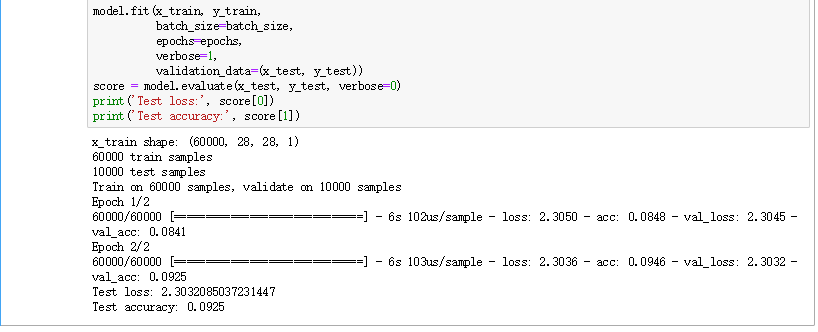

Real-world examples where feature engineering has made a significant difference in things like:
Risk ManagementImage ClassificationNatural Language Processing (NLP)Fraud DetectionAnd many more..
So, now you might got the idea why feature engineering is a crucial, necessary and important step to perform before training a model.
Role of EDA(Exploratory Data Analysis) in Feature Engineering:
If you are not familiar with what EDA is i will like to suggest you to go through my another article on EDA
“In short EDA is basically just analysing and visualising your data.”
The role of EDA in feature engineering is also very crucial because EDA gives us details about our dataset like the relation between columns and what are dependent & independent columns, fetching & removing outliers, correlations, and many more.
By analysing these things through EDA we can further create new feature (columns) to increase the relation between all the independent features and this will let us build a very robust model.
In EDA we also deal with outliers in the dataset and handle missing values.
Now if you have a little domain knowledge about Feature Engineering you might know about Curse of Dimensionality and the question can rise in your mind like how dimensionality can effect your model? How feature engineering can help to reduce it?
What is Curse of Dimensionality?
Curse of Dimensionality means nothing but just tells us that having huge number features (columns) may not result in increasing your model accuracy but can lead to degradation of model accuracy.
How can you deal with Curse of Dimensionality?
To deal with Curse of Dimensionality we have some methods like PCA(Principal Component Analysis), PCA is a very popular and robust methods used to increase model accuracy by decreasing the number of feature and using the features which more likely effect the target value.

Feature Engineering can be done by performing:
Feature Transformation
Feature Construction
Feature Selection
Feature Extraction
Feature Transformation:
It is understood by it name that in this part/ step of feature engineering we (the developer) try to transform the Features available in a dataset of different kind to a one universal kind. Like changing the categorical features to number by using ONE-HOT-ENCODING or LABLE-ENCODING, or changing huge numerical values to a scale by Scaling the Features.
This is one of the basic and most crucial step in preparing a model because it makes the dataset consistent and all the features universal which creates a very positive impact on the model accuracy.
Features Construction:
This step is little complicated if you don’t have the domain knowledge of the dataset you are using but no worries visualisation is available to make it easy.
This is a step in which we try to create new features out of the existing features which could be useful and have a positive impact on the model prediction or accuracy.
Feature construction aims to extract meaningful information from the data and represent it in a way that is more suitable for the machine learning algorithm to learn from. It involves transforming the raw data into a set of input features that are more informative, discriminatory, and relevant to the problem at hand.
Feature Selection:
This is also a step which require the domain knowledge of the dataset to perform task on it but as a human it isn’t possible to have knowledge of every thing so it quite alright because we have techniques like Principle Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE).
These PCA and t-SNE are dimensionality reduction techniques which helps us to select the important features from a dataset which have too many features (big dimension).
Dimensionality reduction techniques like PCA and t-SNE play a very crucial role when dealing with datasets that have a high number of features or a large dimension. In such cases, it can be challenging to extract meaningful insights or build effective models due to the curse of dimensionality.
Feature selection is the process of identifying the most relevant features that contribute the most to the predictive power of the model. By selecting a subset of features, we can simplify the dataset, reduce noise, and improve the model’s performance and interpretability. However, manual feature selection can be a daunting task, especially when dealing with a large number of features or complex relationships.
Feature Extraction:
This step is from my learning knowledge is all visualisation based task, this step is performed, once we had performed Feature Selection. This involves visualising the selected important features and seeing which features has the most heavy impact son the target values and once we got to know that this step end and we use those features as our training features and build a model.
Ending this by saying that feature engineering is an art that combines domain knowledge, data exploration, and various techniques to transform raw data into meaningful features. It is a crucial step in the machine learning pipeline that enhances model accuracy, interpretability, and efficiency. By understanding the concepts and applying appropriate feature engineering techniques, data practitioners can unlock valuable insights and build powerful models that drive impactful results.